VLASH 리뷰
VLASH: Real-Time VLAs via Future-State-Aware Asynchronous Inference
Ⅰ. Introduction
- Motivation
- VLA 모델들의 inference시 synchronous inference으로 delay가 발생하는 문제
-
SmolVLA는 asynchronous inference로 어느정도 이 문제를 해결함
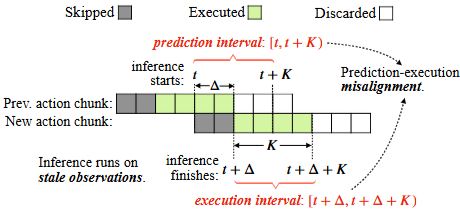
- 그러나, inference의 delay로 misalignment문제가 발생함.
- Asynchronous inference & its problem
- 1번 action chunk와 2번 action chunk가 있다고 가정하면, 1번 action chunk를 수행(execute)하는 동안 2번 action chunk를 inference하는 것임. (비동기적)
- 그런데 보통 execution(1번 수행)하는 시간이 inference(2번 만들기)하는 시간보다 긺.
- execute하는 동안에 inference가 시작되기 때문에, prediction interval은 [t,t+K)이지만 execution interval은 실제 inference가 끝나는 시점인 [t+delta, t+delta+K)임. 이 prediction과 execution의 간극이 있음.
- 즉, 새로 만들어진 2번 action chunk는 inference가 끝나는 시간부터 바로 실행되는데, 그 와중에도 계속 1번 action chunk 가 수행하고 있었으므로 state과 action사이의 간극이 벌어짐.
- 이를 해결하기 위해 Future-State-Aware인 VLASH을 제안
Ⅱ. Method
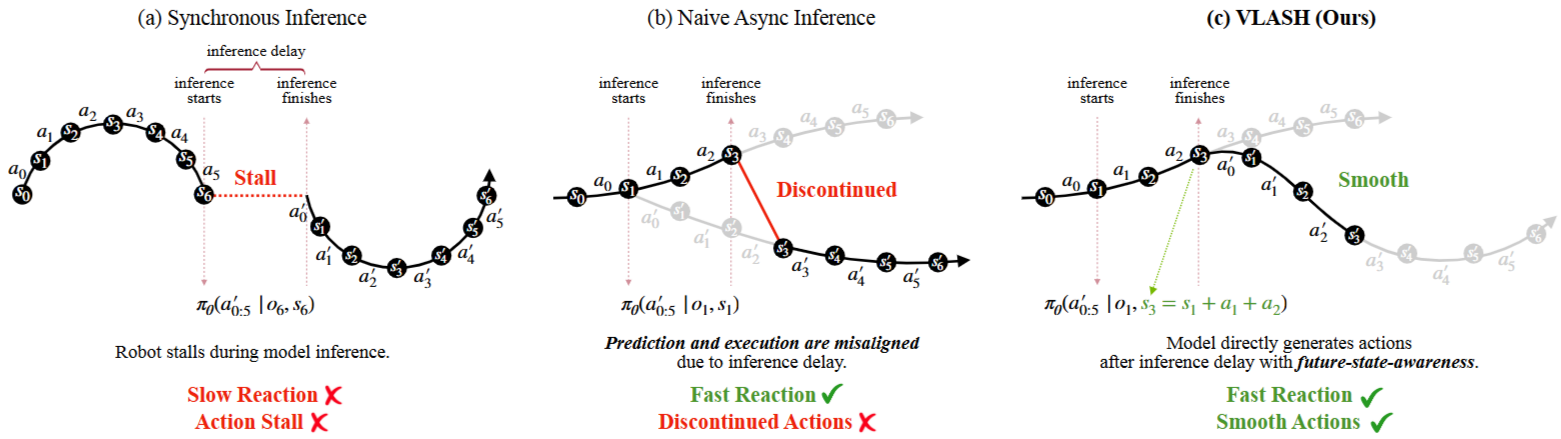
- Inference 시작 시간(t)에 inference 종료 시간(t+Δ) 시점의 observation과 state을 알아야 action을 알 수 있음
- 그러나 future observation은 알 수 없고, 대신 future state은 알 수 있음 (inference 시작 시에 이미 action을 알기 때문임 - from previous chunk)
- 따라서 어떻게 보면 ‘근사’한다고 말할 수 있음
- Offset Augmentation
- Offset state and action together
- random offset 𝛿 → 모델마다 inference 속도가 다르므로
- (training target) future state과 future action chunk를 모두 offset시킴
- observation은 fix
- 당연하게도 same visual input
o_t를 사용함
- 당연하게도 same visual input
→ VLA모델들은 주로 robot state보다 visual input에 rely함 → 이에 대한 근거가 없음. where?
→ 동일한 시각 이미지가 주어져도, 로봇의 오프셋된 미래 상태에 따라 다른 정답 액션에 대응함을 학습
→ 이를 통해 모델이 시각 이미지(observation)에 오버피팅되기보다 state에 집중하도록 유도
- Offset state and action together
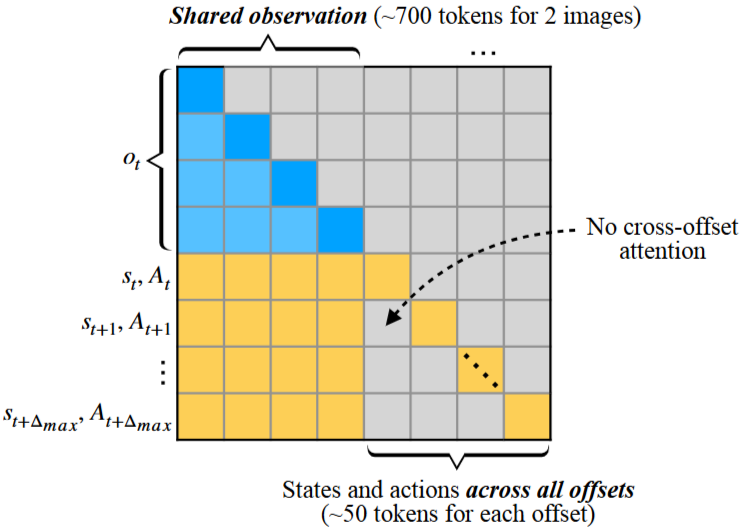
- Efficient Fine-tuning with Shared Observation
- 단순하게 구현하면, 각 δ 값에 해당하는 (o_t, s_t+δ, A_t+δ) 쌍을 독립적인 학습 샘플로 간주
- 그러나 모든 쌍이 동일한 observation인
o_t를 사용하므로 중복됨→ inefficient- 보통 observation token이 action보다 긺 (Pi-0.5에서는 observation 700개 / state& action chunk는 작은 50개)
- 이러한 inbalance가 문제되지는 않을까?
- 이를 위해 모든
s_t,A_t쌍과o_t를 매우 긴 하나의 시퀀스로 취급하여 attention- o_t는 모든 다른 token에 attend하지만 각각의 오프셋들 (s,A) 은 서로 attend하지 않음
- No cross-offset attention
-
Action quantization
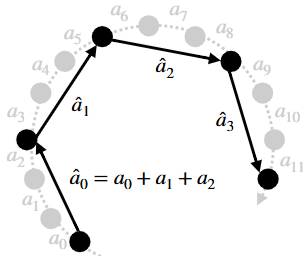
- Async+VLASH로 inference time을 사라지게 만들수 있음. (더 이상 문제가 아님)
- 그렇다면 speed는 거의 execution time에 제약되는 것
- 근데 async도 이상적으로 보면 inference time이 거의 0에 가까우면 상관없는거 아닌가???
- 이게 현실적으로 불가능 한거겠지..?
- 어떻게 execution time을 줄일 수 있을까? → action quantization
- 근데 이게 근본적인 해결책은 아닐 듯
Ⅲ. Experiments
-
Performance. How does our method compare to synchronous control, naive asynchronous and baselines in terms of accuracy and latency?

- execution horizon (K)가 늘어나고, inference delay가 커져도 다른 method는 급격한 성능하라을 보이는것에 반해 꽤 robust함 → 근데 이건 sync가 더 잘하는거 같음 (당연하겠지만)
-
Generalization. How well does our method generalize across different inference delays? Does it hurt the original model performance? How well does our method generalize across different VLAs?

- delay가 커질수록 speedup 면에서는 성능이 좋아지지만 success rate가 낮아짐
- 왜일까? 이는 아무래도 observation이 그대로인 상태에서 state만 바꿨기 때문이 아닐까?
-
Speed-accuracy trade-off. What is the speed-accuracy trade-off of action quantization at deployment?
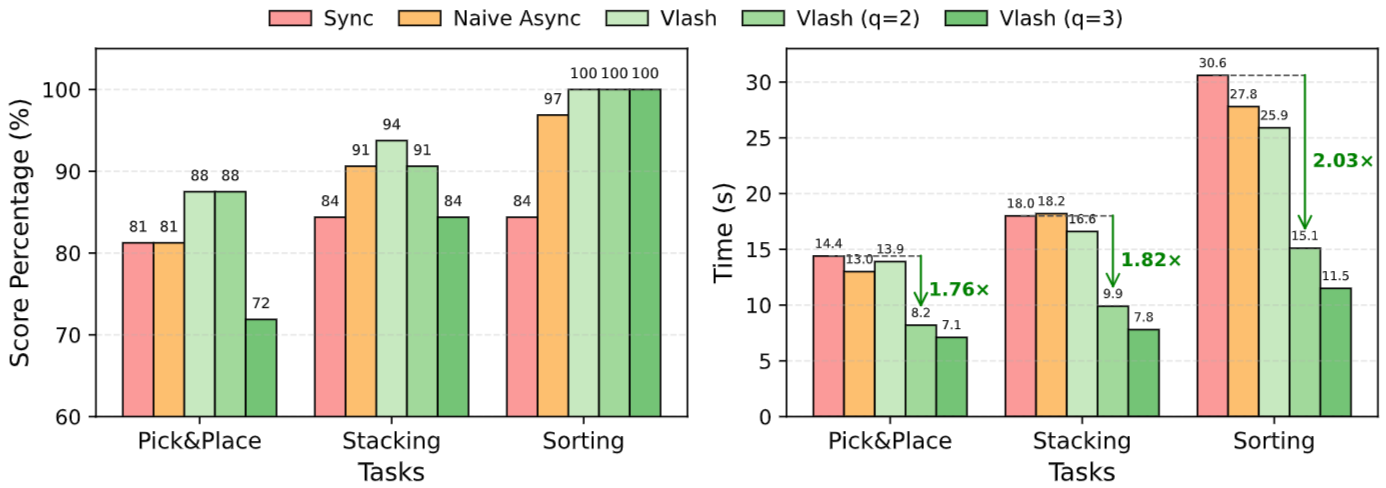
- 반면 Real-World task에서 sync보다도 대체로 좋은 성능을 보임
- 또한 time 또한 매우 빨라짐
- 이는 real world task가 LIBERO보다 더 delay 가 심하기 때문이 아닐까 ? 아니면 state의 변화가 더 크기 때문에 더 효과적인게 아닐까?? 생각이 듦
-
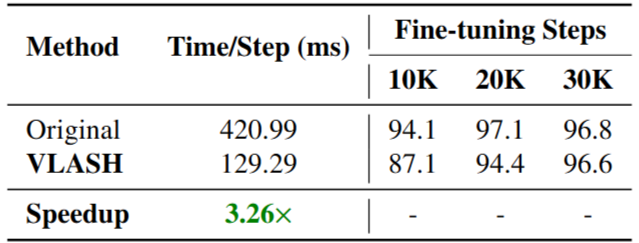
Fine-tuning efficiency. How does our method compare to the standard fine-tuning in terms of training cost and data efficiency? How much the shared observation fine-tuning can reduce the training cost?
- 확연히 shared observation을 공유하면 finetuning이 빨라짐
Ⅳ. Conclusion & Limitation
- Inference delay가 심하면 success rate이 꽤 떨어짐.
- 꽤 robust하지만, 모든 문제를 해결하진 않는 것 같음
- Simulation과 Real world에서의 성능 차이 (baseline에 대한 성능이 simulation에서는 delay의 개수가 크면 오히려 success rate이 떨어졌지만, real world에서는 올라간 점)
- 두 task의 다른 점이 무엇이고, 이러한 차이점이 어디서 기인했는지가 궁금함
- 또한 센서나 network delay에 대해서도 더 나은 성능을 보일 수 있을까?
- observation과 action 토큰의 개수를 다르게 했을 때 (action&state토큰의 개수를 늘린다던가) 어떤 변화가 있을지 궁금함