XVLA 리뷰
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Ⅰ. Introduction
- Motivation
- Data Heterogeneity (이질성/다양성) in Robot :
- Embodiment-specific action spaces
- Setup variations such as camera settings, visual domains, task distributions
- 기존 VLA 모델에서는 이러한 문제가 고려되지 않고, 별도의 action decoder을 통해 다양한 action space를 매핑하는 것만 고려되었음.
- 이러한 문제는 (1) 하드웨어 플랫폼 간의 불일치 (2) 표준화된 데이터 수집 프로토콜의 부재 (3) 내재적인 domain shift 로 인해 해결되지 않음
- Data Heterogeneity (이질성/다양성) in Robot :
- Soft Prompt
- Soft Prompt 를 통해 VLA 모델이 domain-specific한 하드웨어 설정을 배울 수 있음 →
- What is Soft Prompt?
- 소프트 프롬프트는 사람이 읽을 수 있는 단어가 아니라, 모델이 처리하는 연속적인 숫자 벡터(Embedding) 형태의 프롬프트
- Our soft-prompts are represented as a parameter Pe ∈ Rp×e, where p is the length of the prompt (The Power of Scale for Parameter-Efficient Prompt Tuning)
- 다양한 하드웨어 구성 및 데이터 유형을 작업별 특징의 틀에 맞게 재구성 (prompt learning)
- Contribution Overview (?)
- Soft-prompted Transformer (Flow matching DiT + Soft Prompt 추가)
- Training Recipe
- Pretraining: 290K episodes from Droid, Robomind, Agibot
- Domain adaptation: with backbone frozen, soft prompt optimization
- 0.9B라는 놀라운 모델 크기..
Ⅱ. Method
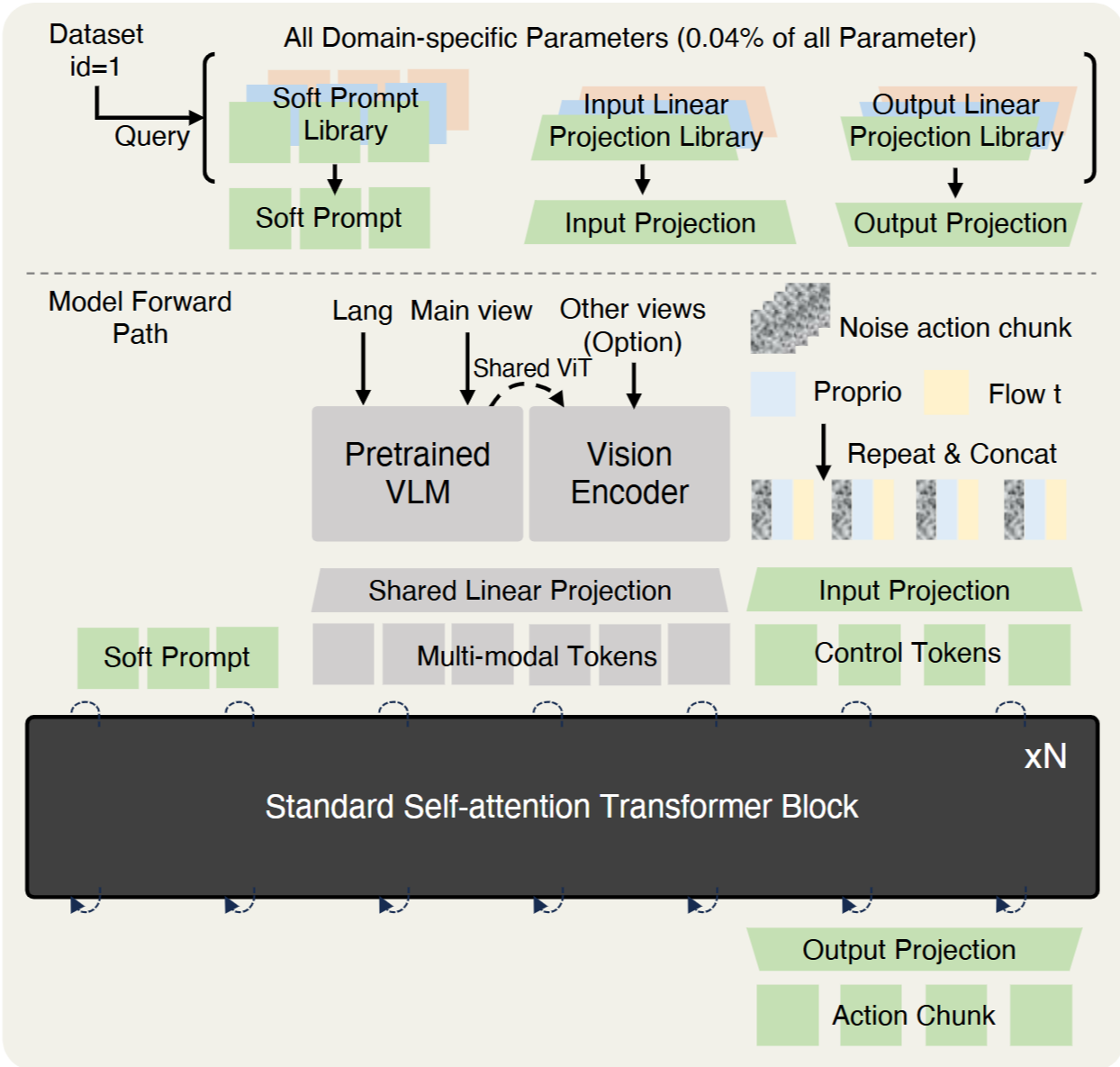
Architecture.
- Architecture
- Contribution을 강조하기 위해 그림이 이상하게 그려졌지만 결국 (1) VLM과 (2) DiT action transformer block의 Dual system 임.
-
저자는 앞서 언급했던 Heterogeneity 문제 해결을 위해 여러가지 방법을 시도해본 것 같음.
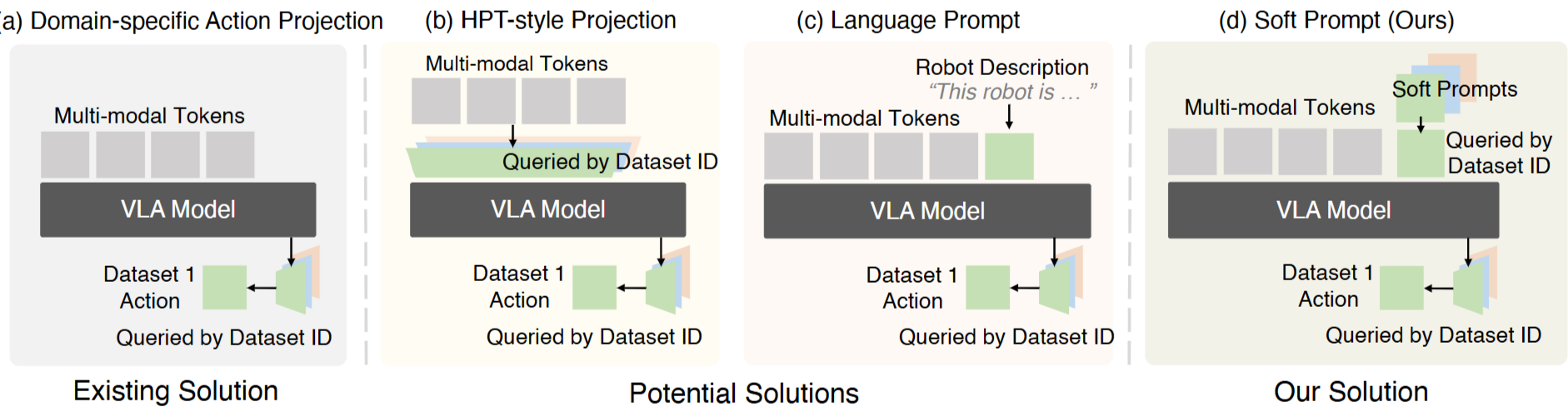
- Domain-specific action projection (기존 방법)
- HPT(Heterogeneous Pre-trained Transformers)-Style Projection (새로운 방법 (1))
- 서로 다른 observation 을 각각의 projection layer을 통해 공통된 representation space으로 맞추는 방식
- 장점: domain discrepancy 해소
- 단점: feature distribution이 바뀌는 문제점 (pretrained된 VLM - 이미 알고있던 정보를 해침)
- 서로 다른 observation 을 각각의 projection layer을 통해 공통된 representation space으로 맞추는 방식
- Language Prompt
- 로봇의 하드웨어 구성을 자연어 설명(텍스트)로 작성하여 추가 입력값으로 제공하는 방식
- 장점: explicit하게 모델이 이해할 수 있음
- 단점: Adaptation 과 Scaling이 어려움
- 로봇의 하드웨어 구성을 자연어 설명(텍스트)로 작성하여 추가 입력값으로 제공하는 방식
- Soft Prompt
- 도메인별로 학습 가능한 파라미터를 도입하여, 하드웨어 구성 정보를 Latent mapping (Φ)
- Φ는 language prompt의 hard template이 아니라 random init돼서 implicit하게 end-to-end optimized됨.
- 장점: b와 c의 단점 해결 (preserve pretrained representation + scalable)
- Input Details
- High-dim inputs (사진+instruction)
- Main(fixed view- 아마 front image일듯) 과 auxiliary view(wrist image) 가 각각 다른 encoder로 들어감.
- Wrist image가 noisy 하고 fast changing하기 때문에 language와 분리시킴.
- Low-dim states (proprioception + action tokens)
- Time embedding T에 따라 concat해서 사용 (Repeat & Concat)
- High-dim inputs (사진+instruction)
- Training Recipe
- Pretraining: backbone과 soft prompt가 jointly optimize됨
- Finetuning: Adaptation을 위해 two-step 도입
- Prompt warm-up: 새로운 learnable prompt 임베딩은 처음에 pretrained weight이 frozen하는 동안 warm up 됨.
- Joint policy adaptation: backbone과 warmed up된 prompt를 jointly optimize
- Learning Rate을 낮추어 pretrained된 representation으로부터의 catastrophic drift 를 막음
- Data Processing
- Action space: (1) EEF position xyz (2) EEF rotation encoded using Rotate6D (3) Binary gripper
- 굳이 이렇게 한 이유는 Euler Angle(gimbal lock, 360° 경계 문제)과 quaternion(antipodal ambiguity)의 discontinuities 때문이라고 함
- Intended abstraction: demo를 downsample해서 action의 noise를 줄임 (4초 동안 30 anchor point를 정함)
- Data sampling: 기존 Round-robin 대신, 다른 도메인뿐만 아니라 각 도메인에서 다른 trajectory를 diverse하게 볼 수 있게 데이터를 shuffle함
- Action space: (1) EEF position xyz (2) EEF rotation encoded using Rotate6D (3) Binary gripper
Ⅲ. Experiments
- Scaling
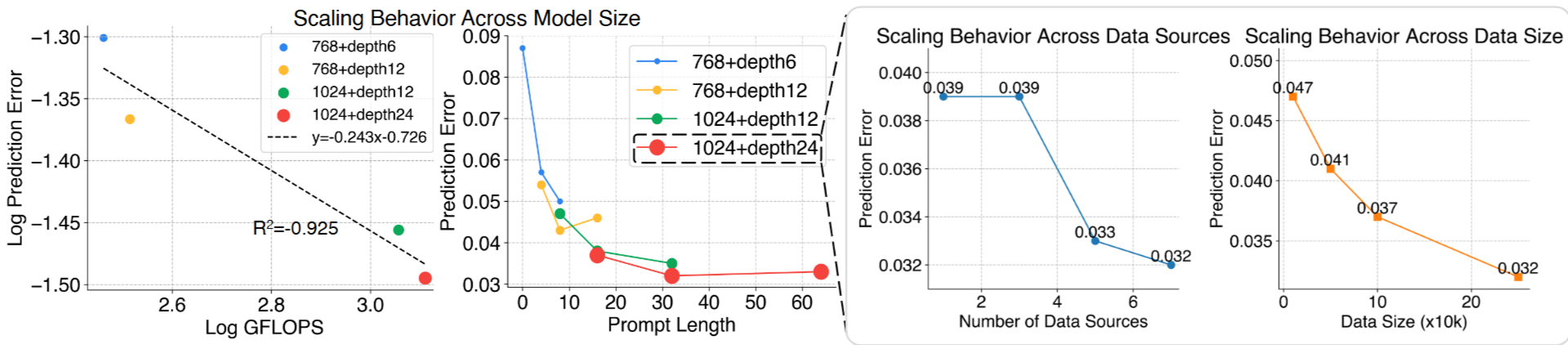
- Adaptation
- 6 simulation (Simpler, LIBERO, Calvin, RoboTwin, VLABench, NAVSIM)
- 3 real world (Simple Manipulation (WidowX), Dex Manipulation (Agilex), PEFT (AIRBOT))
- Soft-Fold라는 옷접기 dataset을 만듦. Bimanual Agilex를 이용
- LoRA를 이용해 parameter의 1%인 9M만 tuning했을때, 결과가 pi-zero와 비슷함.
- In-Depth Analysis
- T-SNE 시각화: Droid 데이터에서 파생된 두 가지 Franka 설정(왼쪽 및 오른쪽 시점)이 서로 분리되지 않고 섞여 있다는 것이 주목할 만한 포인트임.
- PEFT를 통한 adaptation: 사전 학습 시 한 번도 본 적 없는 단일 팔 로봇인 WidowX에 대한 PEFT 실험을 수행했을때, Soft prompt는 무작위 프롬프트나 고정된 사전 학습 프롬프트보다 더 빠르게 수렴하고 더 높은 성공률을 달성(근데 성공률이 50%가 안됨)
Ⅳ. Takeaways
- Soft-prompt를 통해 전이학습의 효과를 낼 수 있다.
- cross-embodiment (generalization) 에 대한 논문이었는데, 뭔가 각각의 task의 성능을 높이는 법 (specialization)에 대한 수행은 부족했던 것 같음.
- 그래도 0.9B만으로 할수있다니 놀랍다. VLM이 VLA에서 차지하는 비율이 너무 높다고 생각했는데, 작은 VLM(Florence-2)을 채택하고, 부족한 능력을 action transformer을 강조하는 방식으로 해결하는 방향이 맞다고 생각된다.